

Building a State-of-the-Art Indic Tokenizer for Nemotron 3 Nano
Introduction
Gnani.ai builds voice and conversational AI for Indian languages across BFSI, insurance, healthcare, telecom, and several other industries. At the core of every model we train and deploy is a tokenizer, the component that converts raw text into the numeric sequences that a language model can process. For Indian languages, tokenizer quality cannot be a secondary concern. It directly determines how efficiently a model reads and generates text, and how much it costs to run.
When we chose NVIDIA Nemotron 3 Nano as the base model for building Gnani.ai’s State-of-the-art Indic Tokenizer, we inherited its tokenizer, originally derived from Mistral Nemo Base 2407, trained primarily on English and European text. The base tokenizer fragments Indian language text heavily: a single word in an Indian language that a skilled reader processes as one unit can expand to four or more tokens under the base tokenizer. Across a full conversation or document, this fragmentation compounds into significant overhead in both compute and cost.
This blog documents how we rebuilt the tokenizer from the ground up, what we measured, the two technical strategies we built and compared, and the results across Hindi, Bengali, Tamil, and Telugu.
What We Set Out to Build
Our goal was to extend the Nemotron 3 Nano tokenizer so that it represents Indian language text as compactly as possible, without retraining the base model or changing its architecture. We focused on four languages that together cover the major script families in our deployments: Hindi and Bengali (Indo-Aryan), and Tamil and Telugu (Dravidian).
The primary metric we optimised for is fertility, the number of tokens produced per word. A tokenizer with lower fertility processes the same text in fewer tokens, which means lower inference cost, more content fitting within the model’s context window, and a cleaner learning signal during fine-tuning. We benchmarked our results against eight publicly available models to understand where we stood in the broader landscape.
We also had a secondary goal: understand why the base tokenizer fragments Indian text as severely as it does, so we could address the root cause rather than patch around it. That investigation led us to build two distinct extension strategies, and the gap between their results taught us something important about how BPE tokenizers work at scale for morphologically rich languages.
Two Extension Strategies
Both strategies, Continued BPE Training and Indic Token Expansion, start from the same place: the Nemotron 3 Nano base tokenizer, with its pre-tokenization behaviour corrected to handle Indian script character boundaries properly. From there, the approaches diverge in how they extend the vocabulary.
Strategy A: Continued BPE Training
BPE (Byte-Pair Encoding) builds a vocabulary by repeatedly merging the most frequently co-occurring adjacent character pairs in a training corpus. The result is not just a list of tokens; it is an ordered table of merge rules that tells the encoder how to apply each token in relation to every other token. When processing a word like வாடிக்கையாளர் (Tamil for “customer”, common in Gnani.ai’s enterprise deployments), the encoder applies these rules sequentially to arrive at the most compact representation.
In Strategy A, we continued this training process directly on the existing Nemotron 3 Nano merge table, using a large, curated corpus of Hindi, Bengali, Tamil, and Telugu text. Each new merge rule is appended to the same ordered merge table that governs the entire base vocabulary. Because every new Indic token is built through the same process as the original tokens, the encoder applies them all in a single consistent pass; there is no conflict between old and new vocabulary entries.
Vocabulary growth is data-driven: a new token is added only when its frequency in the Indic corpus justifies it. High-frequency morphemes, verbal roots, case suffixes, common inflected forms used in conversational speech, earn their place. The target was 32,000+ new merge rules on top of the base vocabulary.
One technical challenge is dependency resolution when splicing new merge rules into an existing table: each new rule may depend on earlier rules that must also be present. Solving this correctly, keeping only the strictly necessary parent merges, was central to making Strategy A work at scale without inflating the vocabulary beyond the intended size.
The key advantage: when Gnani.ai’s Indic Continued BPE tokenizer encounters a word form it has not seen during training, which is frequent in conversational Indian language data or where verbs and nouns combine with multiple suffixes, it can compose that word from its learned constituent merges. Strategy A generalizes by composition rather than by exact-match lookup.
Strategy B: Indic Token Expansion
In Strategy B, we trained a separate tokenizer on Indic corpora at a target vocabulary of 64,000, then decoded its learned tokens back to Unicode strings and added them directly to the base vocabulary using add_tokens(). This approach is faster to implement and has been widely used in the Indic NLP community.
The limitation is structural. Tokens added this way sit outside the BPE merge table; they match only as complete, literal strings. Consider a word like வாடிக்கையாளர்களுக்கு (Tamil, meaning “to the customers”, the dative plural form). If the tokenizer has learned the base form but not this suffixed variant, the entire word falls back to character-by-character encoding. In agglutinative Dravidian languages, where new word forms are built by stacking suffixes, this limitation has a measurable impact on fertility scores in real deployments.
| Strategy A: Continued BPE | Strategy B: Indic Expanded | |
|---|---|---|
| Mechanism | Continues BPE training on the base merge table using Indic corpora | Trains a standalone tokenizer; appends tokens via add_tokens() |
| Compositionality | Full BPE merge hierarchy, new word forms built from parts | Exact string match only, no composition across parts |
| OOV handling | Unseen agglutinated forms composed from constituent merges | Unseen forms revert to byte-level encoding |
| Avg. fertility | 1.8802 (best across all 9 models) | 2.1244 (strong, 34% gain over baseline) |
| Dravidian result | Tamil 1.9969 / Telugu 2.0632, best in field | Tamil 2.2268 / Telugu 2.2764, 10–15% weaker |
Benchmark Results
We benchmarked both Gnani.ai strategies against seven publicly available models on standardised Indic text corpora. The metric throughout is fertility: the number of tokens per word. All nine models were evaluated on the same corpora using the same counting methodology. Lower fertility means fewer tokens, and that is always better.
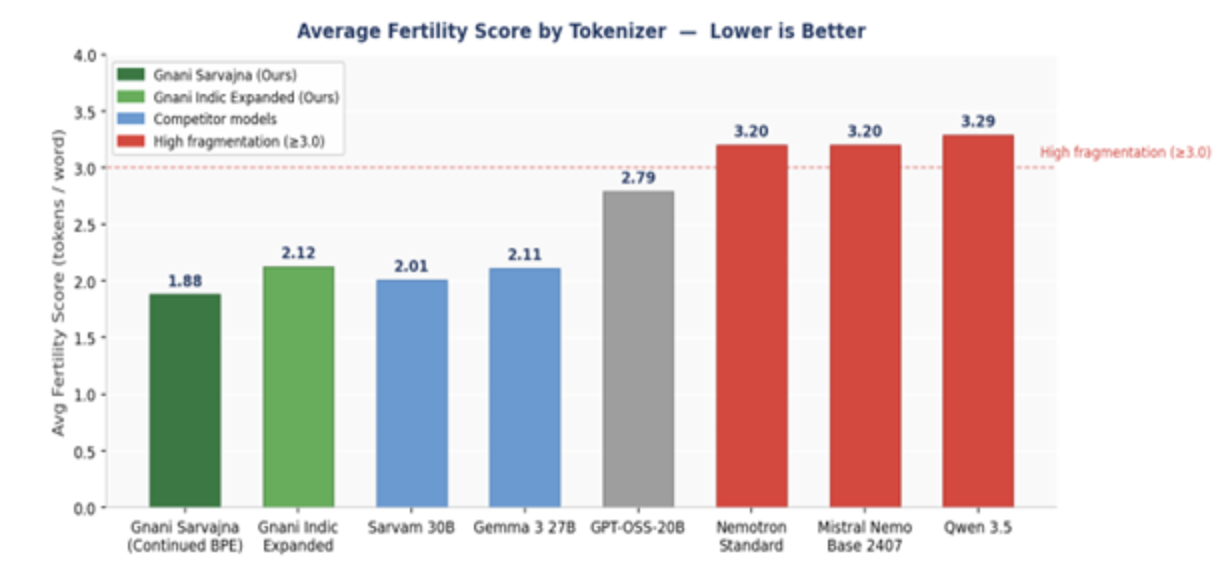
Figure 1: Average fertility score (tokens per word) across all nine tokenizers. Dark green = Gnani.ai models. Red = high fragmentation. Source: Gnani.ai Research, April 2026
Detailed Scores by Language
| Tokenizer | Hindi | Bengali | Tamil | Telugu | Avg |
|---|---|---|---|---|---|
| Gnani.ai Indic Continued BPE | 1.4899 | 1.9709 | 1.9969 | 2.0632 | 1.8802 |
| Sarvam 30B | 1.4093 | 1.6942 | 2.4189 | 2.5026 | 2.0063 |
| Gemma 3 27B | 1.4093 | 1.6942 | 2.4189 | 2.9304 | 2.1132 |
| Gnani.ai Indic Expanded | 1.7623 | 2.2319 | 2.2268 | 2.2764 | 2.1244 |
| GPT-OSS-20B | 1.85 | 2.20 | 3.20 | 3.90 | 2.79 |
| Nemotron Standard | 2.0578 | 3.0697 | 3.7480 | 3.9212 | 3.1992 |
| Mistral Nemo Base 2407 | 2.0578 | 3.0697 | 3.7480 | 3.9212 | 3.1992 |
| Qwen 3.5 | 1.76 | 2.40 | 4.26 | 4.75 | 3.2925 |
Key Findings
Gnani.ai’s Indic Tokenizer leads overall: Strategy A achieves an average fertility of 1.8802 across the four benchmark languages, best in the nine-model field, 6.3% ahead of Sarvam 30B at 2.0063.
Best-in-class for Dravidian languages: Gnani.ai’s tokenizer achieves the lowest Tamil fertility (1.9969) and Telugu fertility (2.0632) across all nine models, 17.5% better than Sarvam 30B on both. Dravidian languages benefit most because their agglutinative morphology, stacking case, tense, and person suffixes onto a root, creates exactly the kind of novel word forms that compositional BPE handles well and flat token appending does not.
Indo-Aryan languages are well-served by both strategies: Sarvam 30B leads on Hindi (1.4093) and Bengali (1.6942). Our training weights were deliberately skewed toward Dravidian improvement, where the gap was largest and least addressed by existing models. Both Gnani.ai strategies still represent a strong result for Hindi and Bengali relative to the unmodified baseline.
Strategy B is a strong independent result: Indic Expanded achieves 2.1244 on average, a 34% improvement over the unmodified Nemotron baseline, but trails Strategy A by 10–15% per language due to the composition gap described above.
English-centric models fragment severely: Qwen 3.5 reaches 4.75 tokens per word on Telugu. Both Nemotron Standard and Mistral Nemo sit above 3.7 on Tamil and Telugu. Any deployment using these tokenizers on Indian-language workloads carries a 2–3x token overhead compared to Gnani.ai’s tokenizer for the same content.
| Language | Family & Morphology | Nemotron Baseline | Gnani.ai Indic Continued BPE |
|---|---|---|---|
| Telugu | Dravidian, heavily agglutinative | 3.9212 | 2.0632 (−47%) |
| Tamil | Dravidian, heavily agglutinative | 3.7480 | 1.9969 (−47%) |
| Bengali | Indo-Aryan, moderately inflected | 3.0697 | 1.9709 (−36%) |
| Hindi | Indo-Aryan, moderately inflected | 2.0578 | 1.4899 (−28%) |
Cost and Inference Implications
Fewer tokens per word translates directly to lower inference cost: a 1,000-word Telugu document produces approximately 2,063 tokens with Gnani.ai Indic Continued BPE versus 3,921 tokens with unmodified Nemotron and 4,753 tokens with Qwen 3.5, roughly half the inference cost for identical content. Context window efficiency improves by the same ratio: at Gnani.ai’s 1.88 average fertility versus the 3.20 baseline, approximately 37% more words fit within a fixed token budget, enabling longer conversation histories, larger document contexts, and fewer truncation-related errors in production. During fine-tuning on Indian language data, fewer tokens per word concentrates the learning signal on meaningful linguistic units, which translates to better morphological understanding from the same amount of training compute.
Conclusion
Building Gnani.ai Indic Continued BPE on Nemotron 3 Nano required us to solve a tokenizer problem before we could solve a language model problem. The unmodified base tokenizer was not designed for Indian scripts, and no amount of fine-tuning on Indian language data compensates for a tokenizer that fragments the text before the model ever processes it.
The comparison between our two strategies confirms that how you extend a tokenizer matters as much as how much you extend it. Strategy A’s fertility advantage over Strategy B comes entirely from the ability to compose unseen word forms from learned parts. For agglutinative Dravidian languages like Tamil and Telugu, where production systems encounter new inflected forms constantly, that compositionality is the difference between leading the benchmark and sitting in the middle of it.
The Gnani.ai Indic Continued BPE tokenizer is now the foundation for all Gnani.ai models trained on Indian language data. The benchmark places it first overall on average fertility (1.8802) and first in class on Tamil and Telugu, the two languages most poorly served by the multilingual tokenizers that Gnani.ai Indic Continued BPE replaces.
About the Authors







