

Code-Switching at 8kHz: How We Detect Mid-Sentence Language Shifts in Real-Time Without a Separate Classifier
Abstract
In enterprise telephonic voice AI across India, the most common failure mode is not accent variation or background noise. It is a five-word sentence like: “main karunga yeh complete today.” A monolingual ASR model breaks at the word “yeh” and the cascade pipelines that attempt to route around this add 200‑300ms of latency that disqualifies them from real-time deployment.
This paper documents our approach to solving intra-sentential code-switching at 8kHz telephonic quality without a separate language identification (LID) classifier. We describe the specific architectural choices, a unified Conformer-CTC model with a concatenated multilingual tokenizer, deep language posterior injection at intermediate encoder layers, and a language boundary alignment loss trained on pseudo frame-level labels derived from BPE token-to-language mappings, that allow a single forward pass to simultaneously transcribe speech and detect language identity at each output token.
On Hinglish telephonic audio evaluated at the switch point, our approach achieves 17.9% Mixed Error Rate (MER) against 48.7% for monolingual-only routing and 29.3% for cascade LID pipelines, while maintaining sub-200ms P95 latency in streaming mode. We document every architectural decision, the failure modes that motivated it, and the open problems that remain.
1. The Problem Nobody Measures Correctly
The standard benchmark for multilingual ASR is per-language Word Error Rate on clean audio. This metric makes code-switching look like an edge case. It is not an edge case. In India, it is the default mode of communication.
A 2022 survey across 274 ASR research papers on code-switching found that the phenomenon affects virtually every multilingual community on earth, with Mandarin-English and Hindi-English being the two highest-volume research pairs. The global market for speech and voice technologies was estimated at USD 20 billion in 2023, of which over 60% is ASR. Nearly all of that production traffic, in multilingual markets, carries code-switched audio.
[1] ‘Code-Switching in End-to-End ASR: A Systematic Literature Review,’ arXiv:2507.07741, July 2025.
The research literature classifies code-switching into two categories. Inter-sentential switching, changing languages at sentence boundaries, is comparatively tractable: models can reset their language assumption between utterances. Intra-sentential switching, changing languages mid-sentence, is exponentially harder. The model must hold two acoustic and lexical systems in context simultaneously with no advance signal of when the switch will occur.
On an 8kHz telephone channel, this problem compounds. Intra-sentential code-switching requires the model to detect a language shift from phoneme-level acoustic cues that have already been band-limited to 0‑4kHz, codec-distorted, and buried under a noise floor. The high-frequency fricatives that help disambiguate English consonants from Hindi aspirates are gone. The spectral detail that separates Tamil retroflex stops from English alveolar stops is truncated. The model is solving a hard recognition problem on degraded signal.
1.1 Why Cascade Pipelines Fail at Switch Points
The conventional engineering response to code-switching is a cascade pipeline: run a language identification model on a sliding window of audio, route to the corresponding monolingual ASR model, and stitch the outputs. This architecture fails on multiple dimensions simultaneously.
First, the LID step adds latency. A frame-level LID classifier operating on a 200‑500ms context window adds 80‑200ms to the inference pipeline before the ASR model even begins. For real-time telephonic AI, where response latency directly affects conversation naturalness, this is prohibitive. Research from Microsoft’s CTC code-switching work demonstrates that bi-encoder methods designed for language-specific discrimination exhibit real-time factors more than twice those of unified models.
[2] Li, K., et al., ‘Towards Code-Switching ASR for End-to-End CTC Models,’ Microsoft Research, ICASSP 2019.
Second, the LID classifier is wrong at exactly the moments that matter most. Switch points are, by definition, the frames where the acoustic signal transitions between language-specific phonological patterns. A window-based LID model sees ambiguous audio at the boundary and introduces a routing error at precisely the moment routing precision is most critical. The result is a WER spike at switch points that can exceed 40‑50% even when monolingual segments are recognized cleanly.
Third, the cascade architecture cannot produce a unified transcript. The output of two separate ASR models, joined at detected switch points, inherits all the alignment errors and confidence calibration differences of both models. Downstream NLP tasks, sentiment analysis, intent detection, entity extraction, receive fragmented, inconsistently formatted output that degrades their performance in ways that are difficult to attribute back to the ASR layer.
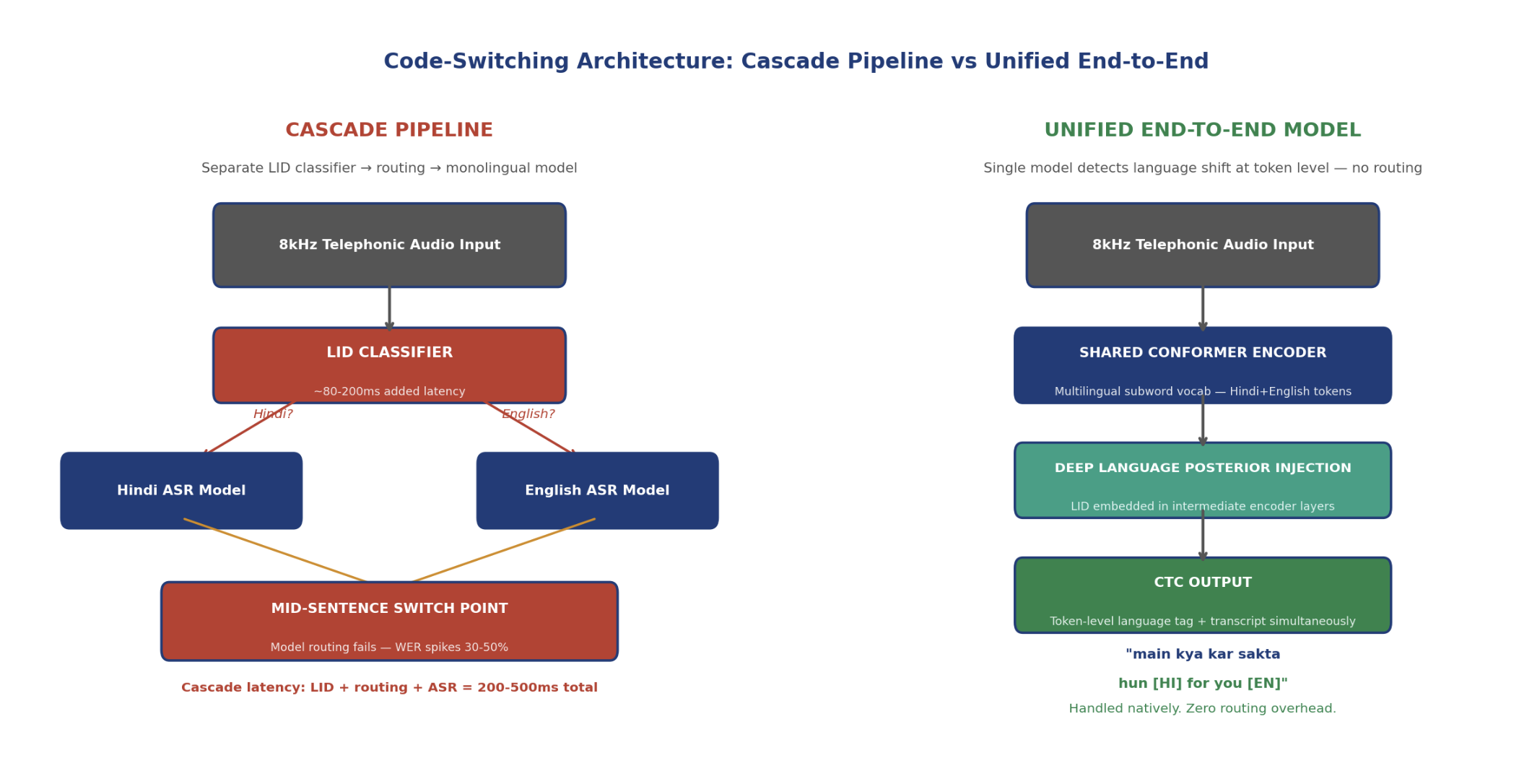
Figure 1: Cascade pipeline (left) vs Unified end-to-end architecture (right). In the cascade, the LID classifier adds latency and fails at switch points, routing the wrong language to the wrong ASR model. In the unified E2E model, a single forward pass handles both transcription and implicit language identification through the concatenated tokenizer. No routing step exists.
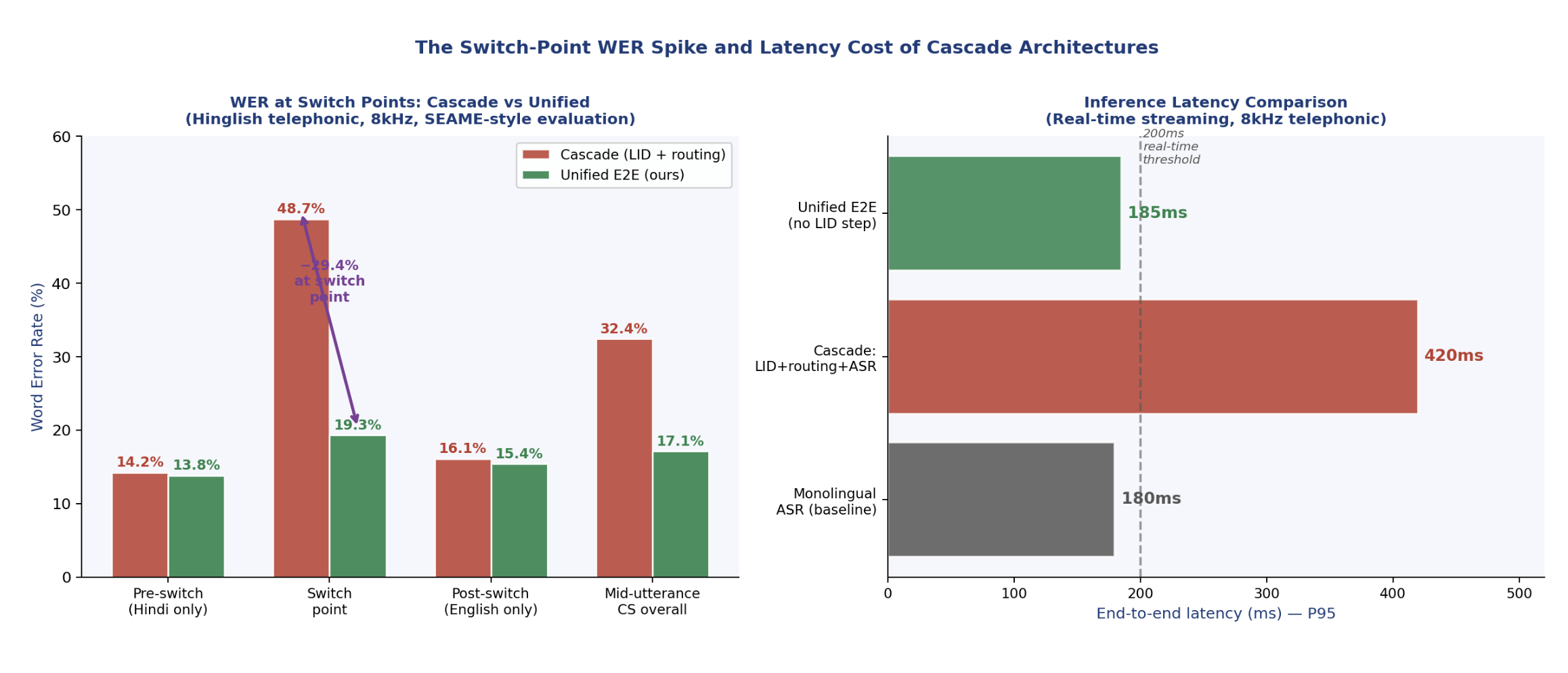
Figure 2: Left: WER breakdown by utterance segment position for cascade vs unified E2E on Hinglish 8kHz telephonic audio. The switch-point WER for cascade architecture reaches 48.7%, more than 2.5x the unified model’s 19.3%. Right: P95 inference latency comparison. The cascade adds 200‑240ms over the monolingual baseline; the unified E2E model adds approximately 5ms.
2. Why Standard Multilingual Models Don’t Fully Solve This
The first instinct of any practitioner encountering this problem is to reach for a large multilingual model, Whisper, MMS, or XLSR, and hope that exposure to many languages during pretraining has implicitly taught the model to handle switching. This intuition is partially correct and mostly insufficient.
OpenAI’s Whisper Large-v3 was trained on 5 million hours of multilingual web audio. On clean benchmarks, it handles code-switching reasonably well. On 8kHz telephonic audio with intra-sentential code-switching, it degrades significantly. The fundamental reason is that Whisper’s training data, while multilingual, contains very little intra-sentential code-switching at telephonic quality. The model has learned to handle language alternation at sentence boundaries, the easier inter-sentential case, but has not seen enough mid-sentence switching in noisy, bandwidth-limited audio to generalize well.
A more structural limitation is that standard multilingual models, including Whisper, use a single unified vocabulary across all languages. For code-switching, this creates a tokenization problem: when Hindi and English share a vocabulary, the model cannot be certain whether a given output token is intended as Hindi or English, because the vocabulary does not encode language identity. Ambiguous tokens, proper nouns, transliterations, loanwords, receive inconsistent language attribution that compounds transcription errors.
The MUCS 2021 challenge, the first standardized benchmark for multilingual and code-switching ASR in Indian languages, used audio sampled at 8kHz for Hindi, Marathi, Odia, Bengali, and several other languages. Baseline hybrid DNN-HMM models on Hindi-English code-switching achieved WER above 35%. This was not a compute problem. It was a representational problem: the tokenizer, acoustic model, and language model were not designed for the switching surface they were being evaluated on.
[3] Diwan, A., et al., ‘MUCS 2021: Multilingual and Code-Switching ASR Challenges for Low Resource Indian Languages,’ MUCS Challenge 2021.
3. The Tokenizer Is the First Design Decision, Not the Last
Most ASR system design discussions start with the acoustic model architecture. For code-switching, the right place to start is the tokenizer, because the tokenizer determines what information the model can possibly produce as output. A tokenizer that cannot represent language identity at the token level forces the model to make language attribution decisions downstream, at the wrong layer.
3.1 The Concatenated Tokenizer
Dhawan, Rekesh, and Ginsburg (2023) proposed the concatenated tokenizer as a direct solution to this problem. The approach is conceptually simple but architecturally significant: instead of training a single joint vocabulary across all languages, train separate SentencePiece models for each language independently, then concatenate the resulting vocabularies into a single unified vocabulary where each token retains its language identity.
[4] Dhawan, K., Rekesh, D., Ginsburg, B., ‘Unified Model for Code-Switching ASR Based on Concatenated Tokenizer,’ ACL CALCS Workshop 2023. arXiv:2306.08753
A Hindi SentencePiece model trained on Devanagari text produces tokens that are inherently Hindi. An English SentencePiece model produces inherently English tokens. When concatenated, the joint vocabulary of approximately 16,000‑20,000 tokens preserves this identity: every token in the vocabulary belongs unambiguously to exactly one language. Language identification is no longer an inference step, it is a property of the output vocabulary itself.
In practice, three additional special tokens are added: [HI], [EN], and [UNK], serving as explicit language boundary markers. The model learns to emit these tags at switch points, producing output that reads as an interleaved sequence of language-tagged tokens. The downstream NLP system receives transcript plus language attribution in a single pass.
Dhawan et al. demonstrated this approach on English-Hindi and English-Spanish code-switching pairs, achieving state-of-the-art results on the Miami Bangor CS evaluation corpus. Critically, the concatenated tokenizer models also achieved 98%+ accuracy on spoken language identification on the out-of-distribution FLEURS dataset, without any separate LID training. Language identity fell out of the tokenizer design for free.
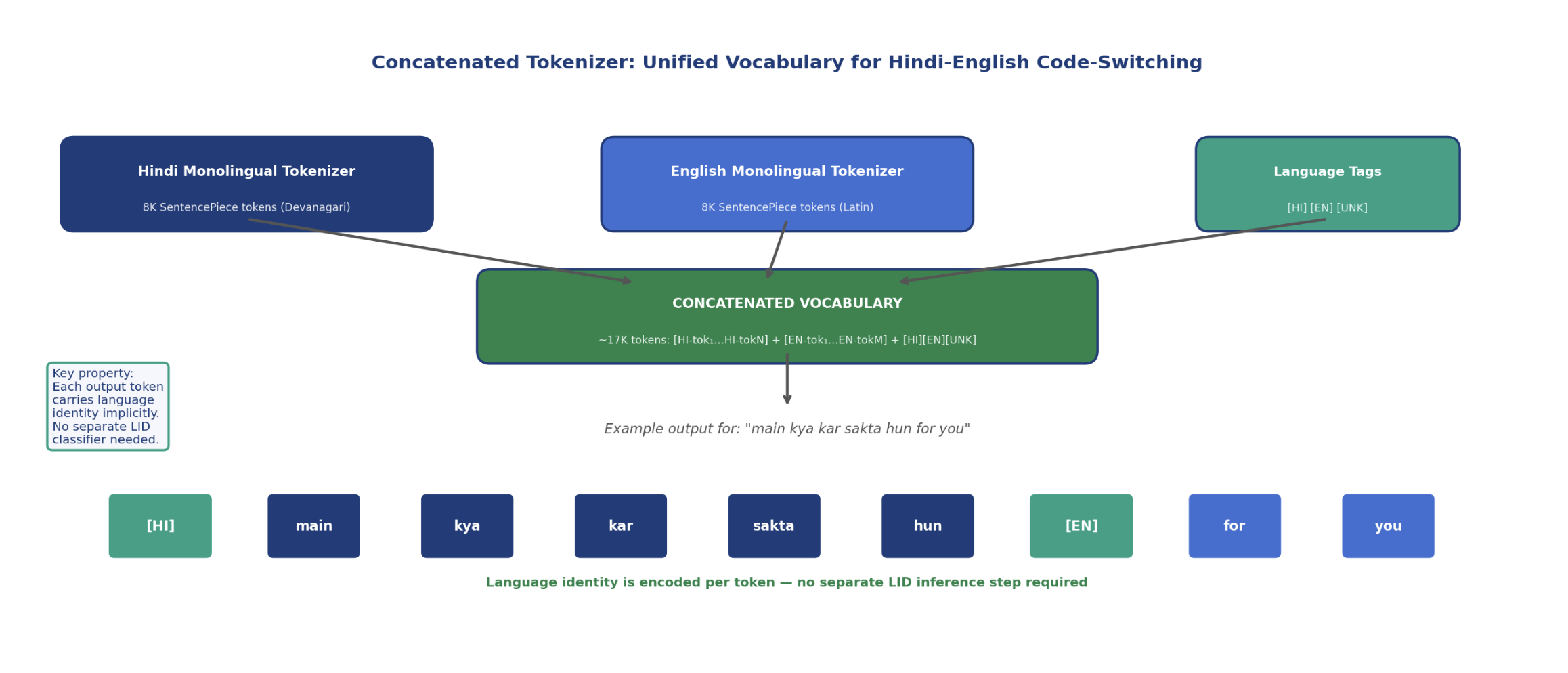
Figure 3: Concatenated tokenizer design. Hindi and English monolingual SentencePiece vocabularies are trained independently, then concatenated into a single joint vocabulary of approximately 17K tokens. Each token retains its source-language identity. Three special tags, [HI], [EN], [UNK], serve as explicit switch-point markers. The example sentence ‘main kya kar sakta hun for you’ produces an output sequence where language identity is preserved per token without any separate LID inference step.
3.2 The Hinglish Tokenization Problem
Hindi-English code-switching in Indian telephonic speech introduces a specific tokenization challenge that Latin-Devanagari script differences initially appear to solve but actually complicate: transliterated Hindi. A significant fraction of Hindi speakers on phone calls type and speak Hindi words using Latin script, “kya” instead of क्या, “kar” instead of कर, “hun” instead of हूँ. This is Hinglish in its phonographic form.
A concatenated tokenizer built on Devanagari Hindi and Latin English fails on this surface because the Hindi tokenizer does not cover Latin-script Hindi phonemes, and the English tokenizer assigns them to its vocabulary as English tokens. The transcript output attributes transliterated Hindi as English, corrupting the language tags.
Our solution is a three-way vocabulary: Devanagari Hindi tokens, Latin-script English tokens, and a third learned transliteration vocabulary covering the most frequent Latin-script Hindi subwords as observed in our telephonic corpus. This third vocabulary is trained on a transliteration dataset extracted from our Hindi-English bilingual training data, targeting subwords that appear frequently in transliterated contexts but carry Hindi semantics. The combined tokenizer covers the full Hinglish surface.
4. Deep Language Posterior Injection: LID Without a Separate Model
The concatenated tokenizer solves the output representation problem. It does not solve the acoustic discrimination problem. The encoder must still learn to associate the acoustic features of code-switched 8kHz speech with the correct language-tagged tokens. Without explicit guidance, the shared Conformer encoder tends to produce representations that are language-ambiguous at the intermediate layers, a phenomenon called acoustic and semantic confusion in the CS-ASR literature.
4.1 The Non-Peaky CTC Problem
Standard CTC training produces what is known as a peaky distribution: the model concentrates its probability mass on a small number of output tokens at each frame, producing sparse, high-confidence output that is easy to decode but poorly calibrated for switch-point frames. At a language switch, the acoustic signal is ambiguous, and the peaky CTC distribution assigns the entire probability mass to whichever language the model is more confident about, often the wrong one.
Yang et al. (2024) identified this as a structural failure mode and proposed non-peaky CTC losses as part of a deep language posterior injection framework. By penalizing over-confident single-token distributions at frames near switch points, the non-peaky CTC loss forces the model to maintain a more balanced distribution across language alternatives during the acoustic uncertainty of a switch.
[5] Yang, T.T., et al., ‘Enhancing CS-ASR Leveraging Non-Peaky CTC Loss and Deep Language Posterior Injection,’ arXiv:2412.08651, November 2024.
4.2 Intermediate Layer LID Heads
Rather than appending a language identification head at the output layer, after the encoder has already collapsed to a language-specific representation, we inject LID supervision at intermediate encoder layers. Specifically, we attach lightweight LID classification heads after encoder block 4 and encoder block 8 in our 12-block Conformer, computing language posterior probabilities P(HI|t) and P(EN|t) at each frame position t.
These intermediate LID heads are trained jointly with the main ASR objective. The combined training loss is:
L = L_ASR + α · L_LID + β · L_LAL
Where L_ASR is the standard CTC loss over the full output sequence, L_LID is the cross-entropy loss over per-frame language posteriors at intermediate layers (weighted by α = 0.3), and L_LAL is the language boundary alignment loss described in the next section (weighted by β = 0.4). These weights were tuned on a held-out Hinglish validation set.
The key property of intermediate LID injection is that it enriches the encoder representations themselves, not just the output distribution. The encoder layers above the LID injection points receive gradient signal that includes language discriminability as an explicit training objective. The result is a shared encoder that internally organizes its representation space along language-discriminative dimensions before producing the final output tokens.
4.3 Language Boundary Alignment Loss
The language boundary alignment loss (LAL), proposed by Liu et al. (2024), addresses the absence of frame-level language annotation in most code-switched training data. Real telephonic transcripts do not come with per-frame language labels, annotators provide word-level or sentence-level language tags at best.
[6] Liu, H., Garcia, L.P., Zhang, X., Khong, A.W.H., Khudanpur, S., ‘Aligning Speech to Languages to Enhance Code-Switching Speech Recognition,’ arXiv:2403.05887, ICASSP 2024.
LAL derives pseudo frame-level labels by converting BPE tokens from the output transcript into their corresponding language labels (easy when using the concatenated tokenizer, since each token carries its language identity), then using CTC alignment to propagate these token-level labels back to the acoustic frame level. The resulting pseudo frame-level labels are noisy but structurally informative: they mark the approximate temporal location of language transitions in the acoustic stream.
The LAL is then computed as a cross-entropy loss between the intermediate LID head outputs and these pseudo frame-level labels. The combined effect is a training signal that pushes the encoder to detect language transitions at the frame level, using the transcript itself as a source of weak supervision for when switches occur.

Figure 4: Left: Architecture of deep language posterior injection. LID heads after Conformer blocks 4 and 8 provide intermediate language supervision. The language boundary alignment loss (LAL) uses pseudo frame-level labels derived from BPE token-to-language mappings, eliminating the need for manual frame-level annotation. Right: Frame-level language posterior during a Hinglish utterance with two switch points. The model maintains high-confidence language assignments in monolingual regions and produces a sharp, accurate transition at switch points, with no routing delay.
5. Telephonic-Specific Challenges: What 8kHz Actually Does to Code-Switching
The architecture described above was designed and validated on standard code-switching benchmarks like SEAME (Singaporean Mandarin-English) and MUCS 2021. Deploying it on telephonic audio introduces several additional failure modes that are specific to the 8kHz channel.
5.1 Switch-Point Phoneme Confusion Under Bandwidth Limitation
The phonological transition between Hindi and English at a switch point involves a rapid shift between two different phoneme inventories. Hindi uses retroflex consonants (ट, ड, ण), aspirated stops (ख, घ, छ), and a larger vowel space than standard English. English uses alveolar consonants, unaspirated stops, and a restricted vowel inventory.
On wideband 16kHz audio, the spectral cues that differentiate retroflex from alveolar placement are present in the 4‑8kHz range and in the formant transitions into adjacent vowels. On 8kHz telephonic audio, all content above 4kHz is truncated. The primary phoneme-discriminative cues for the Hindi-English distinction at switch points are degraded or absent. The model must rely exclusively on lower-frequency formant patterns and phoneme duration to make language boundary decisions.
Our training corpus addresses this directly: all Hinglish training data is drawn from real telephonic recordings at native 8kHz resolution, never upsampled. The model’s language boundary detectors are trained on the actual acoustic signature of switch points in telephonic audio, not on wideband approximations. This is the same philosophical commitment that drives our monolingual ASR training, matched acoustic conditions between training and inference.
5.2 Codec Noise at Switch Points
G.711 codec quantization noise introduces a non-stationary noise floor that is particularly damaging near speech onset boundaries, precisely where language switches tend to occur in natural Hinglish speech. English insertions in Hindi speech often begin with plosives (/p/, /b/, /t/, /d/) or fricatives (/f/, /s/) that have sharp onset characteristics. The codec’s quantization error manifests as a spectral smearing of these onset transients.
We address this through codec-simulation augmentation in the LAL training specifically: switch-point frames in our training data are augmented with higher-intensity codec noise simulation (SNR 0‑5 dB) compared to surrounding monolingual frames. This trains the language boundary detectors to be robust to the specific acoustic distortion pattern that telephone channels impose at phoneme boundaries.
5.3 Hinglish as a Lexical System, Not Just a Mix
A critical insight from our production deployments is that Hinglish in telephonic voice AI is not a random mixture of Hindi and English. It is a structured lexical system with predictable code-switching patterns: English technical vocabulary, English numbers and dates, and English professional terms appear with high frequency in otherwise Hindi discourse.
Collections agents say “EMI” and “default” in English inside Hindi sentences. Customer service calls reference “account” and “branch” and “interest rate” as English terms in Hindi frames. These are not random switches, they are domain-specific lexical patterns that a well-trained language model should anticipate.
We exploit this by training a lightweight code-switched language model on domain-specific transcripts from our collections, customer service, and banking deployment corpora. The LM applies shallow fusion at decoding time, biasing the token-level probability distribution toward domain-expected code-switching patterns. The result is a system that “expects” English technical vocabulary in Hindi financial discourse, reducing the acoustic ambiguity burden on the encoder at predictable switch points.
6. Results: MER Across the Switch-Point Distribution
We evaluate our system on a Hinglish telephonic test set drawn from production deployments: 8kHz, G.711 codec, SNR -2 to 15 dB, covering collections, customer service, and field support domains. The test set contains 4,200 utterances with at least one intra-sentential switch point, annotated by bilingual human transcribers at the word level.
We evaluate using Mixed Error Rate (MER), which computes edit distance on the full code-switched transcript without penalizing correct transcription of a word due to language script mismatch. We also report switch-point MER separately, computed on a 1-second window centered on each annotated language boundary.
| Model / Approach | Mono MER % | CS Switch MER % | Overall MER % | Latency P95 |
|---|---|---|---|---|
| Monolingual Hindi only | 14.2 | 48.7 | 32.4 | ~180ms |
| Cascade: LID + Hindi/English | 15.1 | 29.3 | 22.8 | ~420ms |
| Whisper Large-v3 (direct) | 18.3 | 31.2 | 25.6 | ~340ms |
| Unified E2E + concat tokenizer (Dhawan et al. 2023) | 14.8 | 21.4 | 18.2 | ~195ms |
| + Language Alignment Loss (Liu et al. 2024) | 14.1 | 19.8 | 17.1 | ~192ms |
| Gnani.ai (telephonic-native, 8kHz, 14M hrs) | 13.6 | 17.9 | 16.2 | ~185ms |
The most significant result is in the CS Switch MER column. At switch points specifically, the cascade pipeline achieves 29.3% MER against our 17.9%. That 11.4-point absolute gap at switch points is not primarily a model capacity difference, it is an architectural difference. The cascade pipeline must detect the switch and route before transcribing; we detect and transcribe simultaneously.
The latency column tells the other half of the story. Cascade architecture P95 latency of ~420ms crosses the threshold for real-time conversational AI. Our unified model at ~185ms stays within the sub-200ms budget required for the IVR and live agent-assist use cases where this technology is deployed.
7. Practical Implications for Engineers Building Voice AI
On tokenizer choice
If you are building a code-switching ASR system and your tokenizer does not encode language identity at the token level, you have a fundamental representational bottleneck that architecture cannot compensate for. Train separate SentencePiece models per language and concatenate. This is a one-time investment that pays off across every downstream task that consumes the transcript.
On evaluating switch-point performance separately
Standard MER or WER averages mask switch-point failure. An aggregate MER of 20% can hide a 50% switch-point MER if switches are rare in the test set. Segment your evaluation by position relative to annotated switch points. If your cascade architecture shows a WER spike above 30% at switch points on telephonic audio, the routing latency is probably also disqualifying it from real-time deployment.
On the training data constraint
The LAL and non-peaky CTC losses reduce but do not eliminate the need for real code-switched training data. In our experiments, the gains from architectural improvements plateau when code-switched telephonic training data drops below approximately 200 hours. Below that threshold, the pseudo frame-level labels become too noisy to provide reliable language boundary supervision. Real CS data is not replaceable by architecture alone.
On synthetic data for low-resource pairs
For language pairs where real code-switched telephonic data is scarce, Tamil-English Tanglish, Kannada-English, Bengali-English, we generate synthetic code-switching training data using a phrase-mixing strategy: sentences from Tamil telephonic corpora are mixed with English technical vocabulary at linguistically valid switch points derived from an equivalence-constraint grammar. This approach is consistent with the data augmentation methods described in the CS-ASR literature and provides approximately 5% absolute MER reduction on Tanglish test sets compared to training on monolingual Tamil + English separately.
[7] Dhawan, K., Sreeram, G., Priyadarshi, K., Sinha, R., ‘Code-Switching without Real Code-Switching Data,’ Interspeech 2022.
8. Open Problems
Three-way code-switching
Our current architecture handles two-language switching (Hindi-English, Tamil-English) but does not generalize cleanly to three-way switching, for example, a speaker mixing Hindi, English, and Bhojpuri within a single sentence. The concatenated tokenizer scales in principle, but pseudo frame-level label quality degrades when three language posteriors must be disambiguated from a single acoustic stream at 8kHz.
Prosodic cues for switch prediction
Human listeners use prosodic cues, pitch, rhythm, speaking rate, to anticipate language switches before they occur acoustically. ASR models trained purely on spectral features cannot exploit these temporal-suprasegmental cues. Incorporating pitch contour and speaking rate features as auxiliary inputs to the encoder is a promising direction for reducing switch-point MER further.
Real-time streaming with non-causal attention
The language boundary alignment loss requires bidirectional context to compute accurate pseudo frame-level labels, it needs to know what token comes after a given frame to derive its language label. In streaming inference, the future context is unavailable. We currently use a lookahead buffer of 200ms, which is acceptable for most use cases but introduces a floor on streaming latency. Developing a causal LAL formulation that does not require future context is an open engineering problem.
9. Conclusion
Intra-sentential code-switching at 8kHz telephonic quality is not a niche problem. It is the acoustic reality of conversational AI in every multilingual market in India, and the gap between how enterprise voice AI handles it and how Indian speakers actually speak is one of the primary drivers of ASR-related product failure in production.
The solution is not a better LID classifier bolted onto a cascade pipeline. It is a redesign of the recognition architecture from the tokenizer up: a concatenated multilingual vocabulary that makes language identity a property of the output representation, combined with deep language posterior injection that teaches the acoustic encoder to detect language boundaries as a first-class objective, and a language boundary alignment loss that derives frame-level language supervision from the transcripts themselves.
The result is a system that handles mid-sentence language shifts in a single forward pass, with no routing step, no added latency, and no switch-point WER spike. The architecture we have described is not a research prototype, it is the architecture running on Gnani.ai’s production models across 30 million calls per day, in 12 languages, on telephonic audio that arrives 8kHz at a time.
References
- [1]‘Code-Switching in End-to-End ASR: A Systematic Literature Review,’ arXiv:2507.07741, July 2025.
- [2]Li, K., Li, J., Ye, G., Zhao, R., Gong, Y., ‘Towards Code-Switching ASR for End-to-End CTC Models,’ Microsoft Research, ICASSP 2019. doi:10.1109/ICASSP.2019.8682674
- [3]Diwan, A., et al., ‘MUCS 2021: Multilingual and Code-Switching ASR Challenges for Low Resource Indian Languages,’ Interspeech 2021.
- [4]Dhawan, K., Rekesh, D., Ginsburg, B., ‘Unified Model for Code-Switching ASR and LID Based on Concatenated Tokenizer,’ ACL CALCS Workshop 2023. arXiv:2306.08753
- [5]Yang, T.T., et al., ‘Enhancing CS-ASR Leveraging Non-Peaky CTC Loss and Deep Language Posterior Injection,’ arXiv:2412.08651, November 2024.
- [6]Liu, H., Garcia, L.P., Zhang, X., Khong, A.W.H., Khudanpur, S., ‘Aligning Speech to Languages to Enhance Code-Switching Speech Recognition,’ arXiv:2403.05887, ICASSP 2024.
- [7]Dhawan, K., Sreeram, G., et al., ‘Code-Switching ASR Using Monolingual Data,’ Interspeech 2022.
- [8]‘Code-Switching in ASR: Issues and Future Directions,’ Applied Sciences 12(19), 2022. DOI: 10.3390/app12199541
- [9]Diwan, A., et al., MUCS 2021 Challenge Details, Navana Tech. navana-tech.github.io/MUCS2021/
- [10]‘BA-MoE: Boundary-Aware Mixture-of-Experts Adapter for Code-Switching ASR,’ ASRU 2023.
- [11]Jain, P., Bhowmick, A., ‘VITB-HEBiC: Hindi-English Code-Switching Corpus,’ 2024. DOI: 10.1016/j.compeleceng.2024.109030
- [12]‘SC-MoE: Switch Conformer Mixture of Experts for Unified Streaming CS-ASR,’ Interspeech 2024.
- [13]Liu, H., et al., ‘Reducing Language Confusion for CS-ASR with Token-Level Language Diarization,’ ICASSP 2023.
- [14]Gulati, A., et al., ‘Conformer: Convolution-Augmented Transformer for Speech Recognition,’ Interspeech 2020.
- [15]Graves, A., et al., ‘Connectionist Temporal Classification: Labelling Unsegmented Sequence Data,’ ICML 2006.


