

What Is Word Error Rate (WER)? The Only STT Accuracy Metric That Actually Matters

A vendor tells you their speech recognition system is 97% accurate. Another says their word error rate is under 5%. A third shows you a benchmark chart with numbers that look impressive but come with no methodology attached.
All three are talking about the same underlying question: how well does this system transcribe what a person actually said? And yet none of them are using the same measurement. That gap, between what vendors claim and what your system will actually deliver in production, is where enterprise voice AI projects quietly fail.
Word error rate is the closest thing the speech recognition industry has to a shared standard. It is not perfect. It does not capture everything that matters. But it is the one metric that, if you understand it properly, gives you the ability to ask vendors the right questions, design the right tests, and make a deployment decision you can defend.
This guide covers what word error rate is, how it is calculated, why it can mislead you if read in isolation, what good WER looks like for Indian language speech recognition, and how to use it as a practical evaluation tool before you sign anything.
What Is Word Error Rate in Speech Recognition?
Word error rate (WER) is a metric that measures how many words a speech-to-text system got wrong compared to what was actually spoken. It is expressed as a percentage: a WER of 10% means the system made errors on 10 out of every 100 words in a given audio sample.
The formula is:
WER = (Substitutions + Deletions + Insertions) / Total Words in Reference Transcript
Each of those three error types means something specific.
A substitution is when the system transcribes the wrong word. The speaker says "loan application" and the system writes "lone application." A deletion is when the system misses a word entirely. The speaker says "your account has been verified" and the system writes "your account verified." An insertion is when the system adds a word that was never spoken. Background noise, a cough, or an unclear phoneme gets interpreted as a word.
What makes this formula useful is that it is directly comparable across systems. If vendor A shows a WER of 8% and vendor B shows a WER of 14% on the same test audio, you have a meaningful basis for comparison, provided the test conditions are identical. That last clause is where things get complicated, and we will come back to it.
Why Word Error Rate Is the Standard Accuracy Metric for STT
Before word error rate became the dominant metric, there was no agreed-upon way to compare speech recognition systems. Vendors measured accuracy differently, on different datasets, in different conditions, and published numbers that were essentially incomparable.
WER solved the comparability problem. It is derived from a concept called Levenshtein distance, which measures the minimum number of edits needed to convert one string into another. Applied at the word level, it gives a clean, reproducible number that any engineer can calculate from a ground-truth transcript and a system-generated transcript.
That reproducibility is why WER has remained the standard metric for decades, across both research benchmarks like LibriSpeech and enterprise procurement evaluations. It is not that WER is the most sophisticated possible measure of transcription quality. It is that it is auditable, calculable without proprietary tools, and directly tied to the thing enterprises care about most: did the system write down what was said.
For a deeper breakdown of this and other common speech recognition terms, see our STT Glossary: Every Term You'll Encounter When Evaluating a Speech-to-Text API.
How to Calculate Word Error Rate: A Practical Example
Take a simple example from a customer service call.
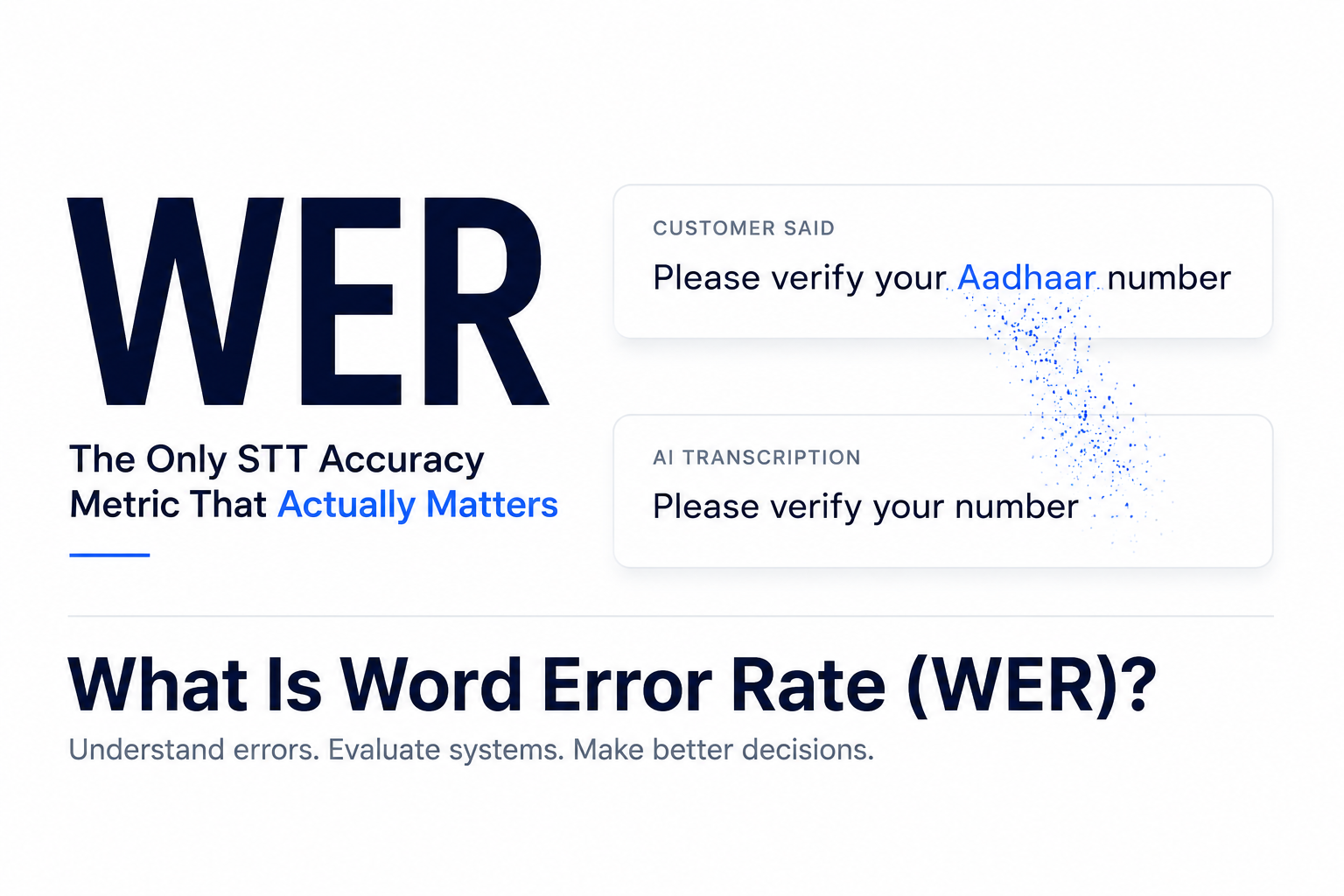
Reference transcript (what was actually said): "Please verify your Aadhaar number before we proceed."
System transcript (what the STT produced): "Please verify your number before we proceed."
The system deleted "Aadhaar." That is one deletion. Total words in the reference: 8.
WER = 1 deletion / 8 words = 12.5%
Now take a harder case from a collections call in Uttar Pradesh, where the agent code-switches mid-sentence.
Reference: "Sir, aapka outstanding amount hai teen hazaar rupay." System: "Sir, aapka outstanding amount hai teen rupay."
The system dropped "hazaar" (thousand). That single deletion changes the amount from three thousand rupees to three rupees, a difference that matters enormously in a collections context.
WER = 1 / 8 = 12.5%, the same number. But the business impact is not the same at all.
This is the first and most important limitation of WER: it treats every word as equally important. A system that drops "hazaar" from a financial amount and a system that drops a filler word like "basically" from a casual conversation can both score 12.5% WER. One has a real-world consequence. The other does not.
The Three Components of WER You Need to Understand
Understanding the error breakdown matters because different error types have different causes, and those causes point to different fixes.
Substitutions typically happen because the acoustic model confuses phonetically similar words, or because the language model does not understand domain-specific vocabulary. In Indian language speech recognition, substitutions often occur at language boundaries, where the model misidentifies a Hindi word as an English word or vice versa. If you are evaluating an STT API for use in environments where code-switching is common, such as BFSI contact centers in Hindi-belt states, a high substitution rate is a signal that the model was not trained on real mixed-language speech.
Deletions often indicate audio quality problems. If your call audio has low bitrate, heavy background noise, or codec compression from a basic 2G connection, the model will miss words because the acoustic signal is degraded. This is particularly relevant for collections deployments in tier-2 and tier-3 cities, where call quality is inconsistent. For a full analysis of how noise degrades transcription quality, see our guide on Speech Recognition in Noisy and Rural India: Why Your STT Fails Where It Matters Most.
Insertions are the least common error type in good systems, but they spike in noisy environments where the model hallucinates words from background sounds. A high insertion rate is a red flag for any STT deployment in busy contact centers or field environments.
When you receive a WER number from a vendor, ask for the breakdown. A 10% WER composed mostly of deletions on noisy audio is a different problem than a 10% WER composed mostly of substitutions on clean audio.
What Is a Good Word Error Rate for Enterprise Deployments?
There is no single answer. WER benchmarks vary significantly by domain, audio quality, and language.
For reference, here is a rough framework based on production deployments:
For English on clean, broadcast-quality audio, top-tier systems now achieve WER in the 3 to 6% range. This is what vendors typically show in their published benchmarks, and it reflects ideal conditions: professional microphones, no background noise, single speaker, standard vocabulary.
For enterprise telephony in English, clean VoIP calls with a single speaker, production-grade systems typically land between 7 and 12% WER.
For Indian languages on telephony audio, the numbers are meaningfully higher across most platforms. Hindi on reasonably clean audio sits between 8 and 18% WER depending on the system. Languages with smaller training data coverage, such as Odia, Assamese, or Punjabi, often show WER above 25% on systems that were not specifically trained for these languages.
This is why vendor benchmarks on English audio are almost entirely irrelevant to an Indian enterprise buyer. What matters is WER on your language, in your use case, on audio that reflects your actual call conditions.
Gnani's STT API achieves under 4% WER across all 12 supported Indian languages: Hindi, Tamil, Telugu, Malayalam, Kannada, Odia, Marathi, Punjabi, Gujarati, Bengali, Assamese, and English. That number comes from evaluation on production telephony audio, not clean studio recordings.
WER vs CER: When Character Error Rate Matters More
Word error rate works well for languages that have clear word boundaries. In English and Hindi, words are separated by spaces. The model either gets the word right or it does not.
For certain Indian scripts, particularly in agglutinative languages where morphological variations change word form significantly, character error rate (CER) is sometimes a more stable measure. CER applies the same substitution-deletion-insertion logic at the character level rather than the word level.
The practical implication: if you are evaluating speech recognition for a language like Tamil or Kannada, ask your vendor for both WER and CER. A system with decent WER but high CER may be getting the right phonemes but producing incorrect inflected forms that break downstream NLP pipelines. For Tamil and Telugu in particular, where verb forms and noun cases are expressed through suffixes, this matters for any use case that involves intent extraction or data structuring.
You will find definitions of both WER and CER, along with other evaluation metrics, in our STT Glossary.
Why Vendor WER Benchmarks Are Almost Always Misleading
Every major STT vendor publishes accuracy benchmarks. Most of them are accurate in the narrow sense that the numbers reflect performance on the specific dataset under the specific conditions described. The problem is that those conditions rarely match enterprise production environments.
Here is what most published benchmarks assume that your production environment does not.
Clean audio. Benchmark datasets like LibriSpeech use high-quality recordings from audiobooks. Your contact center calls come through standard telephony, often 8kHz mono with variable codec compression. WER on 8kHz telephony audio is typically 30 to 60% worse than WER on clean wideband audio for the same model.
Single speaker. Benchmarks are almost always run on single-speaker recordings. Your calls have two speakers, interruptions, cross-talk, and sometimes background noise from the caller's environment. Speaker overlap consistently degrades WER by 15 to 25% in real deployments.
Standard vocabulary. Benchmark datasets contain standard vocabulary. Your calls contain product names, account numbers, regulatory terminology, regional place names, and domain-specific phrases that were never in the training data.
This is why the correct way to evaluate word error rate is not to read a vendor's published number. It is to run your own benchmark on your own audio. For a step-by-step methodology on how to do this for Indian languages, including which test sentence types to use and how to account for code-switching, see our guide on How to Benchmark a Speech-to-Text API on Indian Languages Before You Sign Anything.
The Limits of WER: What It Does Not Measure
Word error rate is a necessary evaluation metric. It is not sufficient on its own. Here is what it misses.
Domain accuracy. A system can achieve low overall WER but systematically fail on the vocabulary that matters most in your use case. If your STT API consistently misrecognises "NPA" as "MPR" or mishears account numbers, the WER impact may be small as a percentage but the business impact is severe. This is why domain-specific testing, using scripts drawn from your actual workflows, matters as much as general WER.
Latency. WER tells you nothing about how fast the system produces a transcript. For real-time use cases, such as live agent assist, call quality monitoring, or voice bots, a system with excellent WER but 800ms latency is not usable. Latency is a separate evaluation axis entirely.
Speaker diarization accuracy. In a two-party call, you need to know not just what was said but who said it. WER does not capture whether the system correctly attributed words to the right speaker.
Downstream NLP compatibility. If your transcripts feed into an NLP pipeline for sentiment analysis, intent classification, or compliance flagging, what matters is not just raw WER but whether the errors cluster in ways that break downstream models. A 9% WER composed of random substitutions may be more tolerable than a 6% WER where the errors consistently fall on entity names, amounts, and dates.
For a full breakdown of the evaluation metrics that matter beyond WER, including diarization accuracy, confidence scoring, and latency measurement, see our guide on Speaker Diarization, Confidence Scores, Latency: The STT Features Enterprises Overlook Until It's Too Late.
How to Use WER in an Enterprise STT Evaluation
If you are building a formal evaluation process, here is a practical approach to making WER useful rather than misleading.
Start by building a representative test set. Pull 200 to 500 call recordings from your actual production environment, covering the range of use cases, languages, agents, and call types you expect to handle. If you are evaluating for a BFSI contact center with operations across Hindi, Tamil, and Telugu regions, your test set should reflect that language distribution.
Have those calls manually transcribed by native speakers of each language. This is your ground truth. The quality of your ground truth determines the reliability of your WER measurement. Poor ground-truth transcription is a common failure mode in vendor evaluations.
Run each candidate system on the same audio. Calculate WER independently for each language. Ask for the error breakdown: substitutions, deletions, insertions. Pay particular attention to errors on high-stakes vocabulary: amounts, dates, account identifiers, and product-specific terms.
Test under degraded audio conditions. Include calls from mobile connections, noisy environments, and low-bandwidth connections in your test set. WER on clean audio tells you what the ceiling is. WER under realistic conditions tells you what you will actually get.
Compare WER alongside latency, diarization accuracy, and API reliability. WER is the primary accuracy metric but not the only deployment-relevant metric.
For a detailed methodology including jiwer-based evaluation across all 12 Indian languages supported by Gnani's STT API, see our full benchmarking guide.
Word Error Rate for Indian Languages: What the Numbers Actually Look Like
Most global STT benchmark reports focus on English. WER performance for Indian languages across major platforms tells a different story.
Hindi is the best-resourced Indian language in most global STT systems, but even here the gap is significant. For production telephony audio with code-switching between Hindi and English, WER for most global platforms ranges from 18 to 28%. For languages like Odia, Assamese, and Punjabi, which have limited training data representation in global models, WER on telephony audio regularly exceeds 30 to 40%.
The problem is not just the lack of training data. It is the mismatch between the audio conditions the models were trained on and the audio conditions of real Indian enterprise deployments. Indian contact center calls typically come in at 8kHz, often with GSM codec compression, with two to three speakers, in environments that include background office noise. Most global models were not trained on this audio profile.
Gnani's STT API was built specifically for Indian production environments. The training data comes from real telephony audio across all 12 supported languages, not cleaned or upsampled recordings. For English on noisy telephony audio, Gnani STT API achieves under 4% WER. Across Indian languages, it delivers 10 to 20% better accuracy than other ASR providers when tested on equivalent production audio.
For a direct comparison of WER performance across Indian languages between Gnani's STT API, Google Cloud Speech-to-Text, and Azure, see our STT API comparison guide.
A Quick Note on WER for BFSI and Regulated Deployments
In financial services, the stakes of transcription errors are higher than in most other domains. A substitution that changes a loan amount or misidentifies a policy number is not just an accuracy problem. It is a potential compliance failure.
For BFSI deployments, the threshold for acceptable WER is lower. A contact center running general customer service can often tolerate 10 to 12% WER if the errors cluster on low-stakes words. A collections workflow, where amounts, account numbers, and consent confirmations need to be captured accurately, requires WER well below 8% and specifically low error rates on financial vocabulary.
Domain-specific fine-tuning and vocabulary customisation are the mechanisms that get WER down on financial vocabulary. Any STT vendor you evaluate should be able to demonstrate WER on a financial services test set, not just a general benchmark.
For a deeper look at what BFSI enterprises need to validate before going live with speech recognition, see our guide on Speech Recognition for BFSI: What Indian Banks and NBFCs Must Verify Before Going Live.
Frequently Asked Questions About Word Error Rate
What is a good WER for a contact center STT deployment?
For production telephony audio in English, a WER below 10% is generally considered strong. For Indian languages on real telephony audio, below 8% from a system trained on Indian speech data is the target. Above 15% in any language will create visible problems in downstream workflows.
Is lower WER always better?
Lower WER is generally better, but the more useful question is whether errors fall on words that matter. A WER of 6% composed of errors on filler words is better than a WER of 4% where errors cluster on amounts, names, and dates.
How is WER different from accuracy percentage?
Some vendors quote accuracy as 100% minus WER. A system with 5% WER has 95% "accuracy." The terms are used interchangeably, but accuracy percentages can obscure the error breakdown, so always ask for WER directly.
Can WER exceed 100%?
Yes. If a system inserts many words that were not spoken, the number of errors can exceed the number of words in the reference transcript. A WER above 100% is rare in production systems but indicates a severely miscalibrated model.
Does WER account for punctuation?
Standard WER calculation does not include punctuation. If accurate punctuation matters for your use case, such as in legal or compliance transcription, ask vendors specifically about punctuation accuracy as a separate metric.
What is the difference between WER and MER (Match Error Rate)?
MER is a variant that normalises against the number of matched words rather than total reference words. It is used in some research settings but rarely in enterprise procurement. WER is the standard you should use for vendor comparisons.
How does code-switching affect WER? Significantly.
A system that handles Hindi and English separately may perform well on each in isolation but show WER spikes of 20 to 40% on sentences that mix the two. Always test with mixed-language audio if your use case involves code-switching.
The Bottom Line on Word Error Rate
WER is not a perfect metric. It treats every word as equally important, it does not capture latency, and a vendor can optimise for a benchmark dataset in ways that do not transfer to your actual calls.
But it is the right starting point. It is standardised, calculable, and directly tied to the outcome you care about. A vendor that refuses to share WER data on telephony audio similar to yours is telling you something important. A vendor that shows benchmark numbers without methodology is doing the same.
The right way to use WER is as an input, not a verdict. Build your own test set on your own audio. Ask for the error breakdown. Test across every language you need. And put WER alongside latency, diarization accuracy, and domain-specific performance before making a decision.
For a complete end-to-end evaluation methodology for Indian language STT, including test set construction, vendor benchmarking, and the questions to put in an RFP, see our How to Benchmark a Speech-to-Text API on Indian Languages guide.
Gnani's STT API supports 12 Indian languages: Hindi, Tamil, Telugu, Malayalam, Kannada, Odia, Marathi, Punjabi, Gujarati, Bengali, Assamese, and English. It achieves under 4% WER for English on noisy telephony audio and delivers 10 to 20% better accuracy than other ASR providers across Indian languages. To evaluate Gnani STT API against your own audio, speak to our team.



