
Text-to-Speech (TTS) technology is a type of computational process that converts written or digital text into audible speech. Initially, the audio produced by TTS systems was mechanical and inorganic sounding. This technology has evolved over time to enable computers and other devices to read text aloud in a natural and human-like voice. This blog delves into how this technology works and how it has made delivering a seamless customer experience (CX) much easier.
Significance of TTS in CX Platforms
TTS is most prominently used in voice bots. In situations where an audio file needs to be played to customers over a call, TTS is used.
This finds multiple use cases across industries. One of the significant use cases is outbound payment reminders for telecom companies, banks etc.
Before Real-Time TTS
Traditionally, voice artists used to record audios. These audio recordings were stored in the system and played back to the customer. There were multiple issues with this process.
The issue with using voice artists was that the audio had to be recorded again from scratch to accommodate the smallest of changes. The CX delivered by such systems was pretty impersonal and failed to leave a lasting impact on customers. Recording the audio again and again shot up the operation costs significantly.
These issues were addressed when real-time TTS technology came in the picture. Read on to find out how.
How Real-Time TTS Actually Works
Even with TTS, voice artists record audios but only during training. Real-time TTS technology can reproduce multiple versions of the audio within seconds. This eliminates the need to record the audio multiple times when small changes need to be made to it.
This is an essential feature of both types of real-time TTS systems. The two types are:
- End-to-end TTS
- Two-stage TTS
Click here to check out either of these TTS systems available with Gnani.ai. Read on for more details about both systems.
1. End-To-End TTS
In this system, all the processing is done in a single stage. The text input is processed to create the audio output. The inference time is slightly higher in this system, but the quality of the audio output is better.
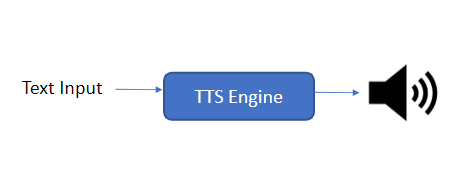
2. Two-Stage TTS
In the two-stage system, the text input is first converted to a spectrogram. This spectrogram is then used to generate the audio. This system has a much faster processing time, so it is used in situations where prompt conversation is necessary to engage customers.
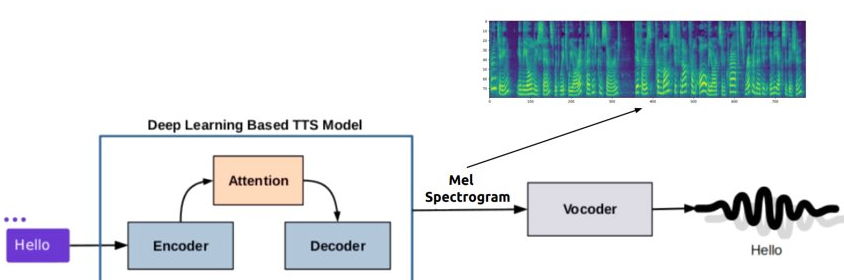
Gnani.ai has gone a step ahead with their innovations. The optimization techniques used by them has reduced the inference time. This has resulted in significantly reduced AHT and in turn, better CX.
Click here for more details on Gnani.ai’s TTS.